


Pesquisadores do MIT desenvolveram uma técnica para permitir que agentes de inteligência artificial pensem muito mais longe no futuro, o que pode melhorar o desempenho de longo prazo de agentes de IA cooperativos ou competitivos. Crédito: Jose-Luis Olivares, MIT, com MidJourney
Imagine dois times se enfrentando em um campo de futebol. Os jogadores podem cooperar para atingir um objetivo e competir contra outros jogadores com interesses conflitantes. É assim que o jogo funciona.
Criando inteligência artificial agentes que podem aprender a competir e cooperar tão efetivamente quanto os humanos continua sendo um problema espinhoso. Um dos principais desafios é permitir que os agentes de IA antecipem comportamentos futuros de outros agentes quando todos estiverem aprendendo simultaneamente.
Devido à complexidade desse problema, as abordagens atuais tendem a ser míopes; os agentes só podem adivinhar os próximos movimentos de seus companheiros de equipe ou concorrentes, o que leva a mau desempenho a longo prazo.
Pesquisadores do MIT, do MIT-IBM Watson AI Lab e de outros lugares desenvolveram uma nova abordagem que oferece aos agentes de IA uma perspectiva perspicaz. Sua estrutura de aprendizado de máquina permite que agentes de IA cooperativos ou competitivos considerem o que outros agentes farão à medida que o tempo se aproxima do infinito, não apenas nas próximas etapas. Os agentes então adaptam seus comportamentos de acordo para influenciar os comportamentos futuros de outros agentes e chegar a uma solução ideal de longo prazo.
Essa estrutura pode ser usada por um grupo de drones autônomos trabalhando juntos para encontrar um caminhante perdido em uma floresta densa ou por carros autônomos que se esforçam para manter os passageiros seguros, antecipando movimentos futuros de outros veículos em uma rodovia movimentada.
“Quando os agentes de IA estão cooperando ou competindo, o que mais importa é quando seus comportamentos convergem em algum momento no futuro. Há muitos comportamentos transitórios ao longo do caminho que não importam muito a longo prazo. Alcançar essa convergência comportamento é com o que realmente nos preocupamos e agora temos uma maneira matemática de possibilitar isso”, diz Dong-Ki Kim, estudante de pós-graduação no Laboratório de Sistemas de Informação e Decisão (LIDS) do MIT e principal autor de um artigo que descreve essa estrutura.
Mais agentes, mais problemas
Os pesquisadores se concentraram em um problema conhecido como aprendizado por reforço multiagente. O aprendizado por reforço é uma forma de aprendizado de máquina em que um agente de IA aprende por tentativa e erro. Os pesquisadores dão ao agente uma recompensa por “bons” comportamentos que o ajudam a atingir um objetivo. O agente adapta seu comportamento para maximizar essa recompensa até que eventualmente se torne um especialista em uma tarefa.
Mas quando muitos agentes cooperativos ou concorrentes estão aprendendo simultaneamente, as coisas se tornam cada vez mais complexas. À medida que os agentes consideram mais etapas futuras de seus colegas agentes e como seu próprio comportamento influencia os outros, o problema logo requer muito poder computacional para ser resolvido com eficiência. É por isso que outras abordagens se concentram apenas no curto prazo.
“Os AIs realmente querem pensar no final do jogo, mas não sabem quando o jogo terminará. Eles precisam pensar em como continuar adaptando seu comportamento ao infinito para que possam vencer em algum momento distante no futuro . Nosso artigo propõe essencialmente um novo objetivo que permite que uma IA pense no infinito”, diz Kim.
Mas, como é impossível conectar o infinito a um algoritmo, os pesquisadores projetaram seu sistema para que os agentes se concentrem em um ponto futuro em que seu comportamento convergirá com o de outros agentes, conhecido como equilíbrio. Um ponto de equilíbrio determina o desempenho de longo prazo dos agentes, e múltiplos equilíbrios podem existir em um cenário multiagente.
Portanto, um agente efetivo influencia ativamente os comportamentos futuros de outros agentes de forma que eles alcancem um equilíbrio desejável do ponto de vista do agente. Se todos os agentes se influenciam, eles convergem para um conceito geral que os pesquisadores chamam de “equilíbrio ativo”.
A estrutura de aprendizado de máquina que eles desenvolveram, conhecida como FURTHER (que significa FULY Reinforcing active influence with average Reward), permite que os agentes aprendam como adaptar seus comportamentos à medida que interagem com outros agentes para alcançar esse equilíbrio ativo.
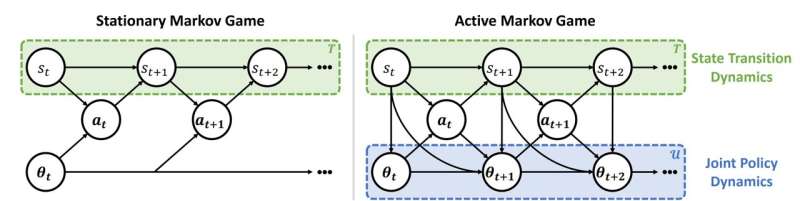
Dentro do cenário de jogo estacionário de Markov, os agentes assumem erroneamente que outros agentes terão políticas estacionárias no futuro. Em contraste, os agentes em um jogo de Markov ativo reconhecem que outros agentes têm políticas não estacionárias com base nas funções de atualização Markoviana Crédito: arXiv (2022). DOI: 10.48550/arxiv.2203.03535
FURTHER faz isso usando dois módulos de aprendizado de máquina. O primeiro, um módulo de inferência, permite que um agente adivinhe o futuro comportamentos de outros agentes e os algoritmos de aprendizado que eles usam, com base apenas em suas ações anteriores.
Essas informações alimentam o módulo de aprendizado por reforço, que o agente usa para adaptar seu comportamento e influenciar outros agentes de maneira a maximizar sua recompensa.
“O desafio era pensar no infinito. Tivemos que usar muitas ferramentas matemáticas diferentes para possibilitar isso e fazer algumas suposições para que funcionasse na prática”, diz Kim.
Ganhar no longo prazo
Eles testaram sua abordagem contra outros agentes multiagentes aprendizagem por reforço frameworks em vários cenários diferentes, incluindo um par de robôs lutando no estilo sumô e uma batalha colocando duas equipes de 25 agentes uma contra a outra. Em ambos os casos, os agentes de IA que usam FURTHER venceram os jogos com mais frequência.
Como sua abordagem é descentralizada, o que significa que os agentes aprendem a vencer os jogos de forma independente, também é mais escalável do que outros métodos que exigem um computador central para controlar os agentes, explica Kim.
Os pesquisadores usaram jogos para testar sua abordagem, mas AINDA poderia ser usado para lidar com qualquer tipo de problema multiagente. Por exemplo, poderia ser aplicado por economistas que buscam desenvolver políticas sólidas em situações em que muitos titulares interagentes têm comportamentos e interesses que mudam ao longo do tempo.
A economia é uma aplicação que Kim está particularmente entusiasmada em estudar. Ele também quer se aprofundar no conceito de equilíbrio ativo e continuar aprimorando a estrutura FURTHER.
O trabalho de pesquisa está disponível em arXiv.
Dong-Ki Kim et al, Influencing Long-Term Behavior in Multiagent Reinforcement Learning, arXiv (2022). DOI: 10.48550/arxiv.2203.03535
Fornecido por
Instituto de Tecnologia de Massachusetts
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisa, inovação e ensino do MIT.
Citação: Novo sistema pode ensinar um grupo de agentes de IA cooperativos ou competitivos a encontrar uma solução ideal de longo prazo competitivo-ai-agents.html
Este documento está sujeito a direitos autorais. Além de qualquer negociação justa para fins de estudo ou pesquisa privada, nenhuma parte pode ser reproduzida sem a permissão por escrito. O conteúdo é fornecido apenas para fins informativos.